
英伟达(NVDA.US)终于成为下一个万亿芯片市场掌舵者
本文来自“虎嗅”。
穿着黑色羽绒马甲,顶着一头凌乱的白发。在今年英伟达最重要的产品发布会上,略显不修边幅的老黄,终于从烤箱里端出了一块让人期待太久,但却又让显卡迷们措手不及的GPU产品。
让人兴奋的,是传闻已两年有余的新架构Ampere ,姗姗来迟的7nm制程,以及实现了大飞跃的性能。对英伟达(NVDA.US)来说,A100,是一个有着跨时代意义的产品。
但它的目标用户,却并非是一手把英伟达捧上神坛的游戏玩家。
这次,英伟达瞄准了一个更大、更有意愿掏钱的金主群体。
一统云服务巨头“后院”
这次的A100,是英伟达的企业级GPU产品 V100的继任者,专门为数据中心“玩家”而打造。
后者在2017年一经推出,就在两年内获得了巨大成功,直接打入了包括亚马逊、微软、阿里以及腾讯等云服务巨头的数据中心核心地带,成为各家GPU计算服务团队不可缺少的芯片产品。
至于为何在这个市场一路畅通无阻。一方面,是GPU的并行运算结构对训练机器学习和深度学习模型有着天然优势。
云服务商早已集体默认,与人工智能相关的任务,从数据处理效率、功耗等多方面考虑,使用GPU进行模型训练是最好的选择之一。
无论是阿里还是腾讯云,与GPU相关的产品页面,基本都涵盖了像英伟达V100与T4等热门型号的企业级GPU产品。
一位阿里工程师告诉虎嗅,目前几乎所有的感知类深度学习任务,都需要用到大规模深度学习,必须基于多机多卡进行模型训练。
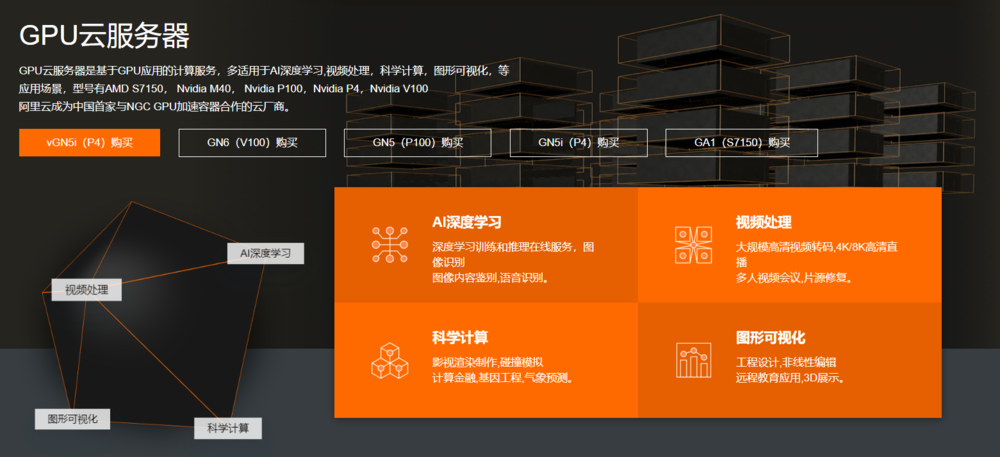
图片截自阿里云
而A100,据英伟达声称其在人工智能推理和训练方面比 V100要快近20倍。对此,自动驾驶公司文远之行技术总监钟华给出了更加细节化的解释:
实际上,人工智能开发者最关心的是FP16(单精度浮点数)与int8(用8bit的内存,存储一个整数数据;类似于数据类型,常用于推理模型)这两个重要参数。从两者的数据来看,其计算力相比V100提高了两倍不止。
此外,他还指出,在内存带宽这个指标上,A100比V100提升了40%以上,这意味在高速模型的训练上面是非常有帮助的,特别是自动驾驶所需要的实时训练模型。
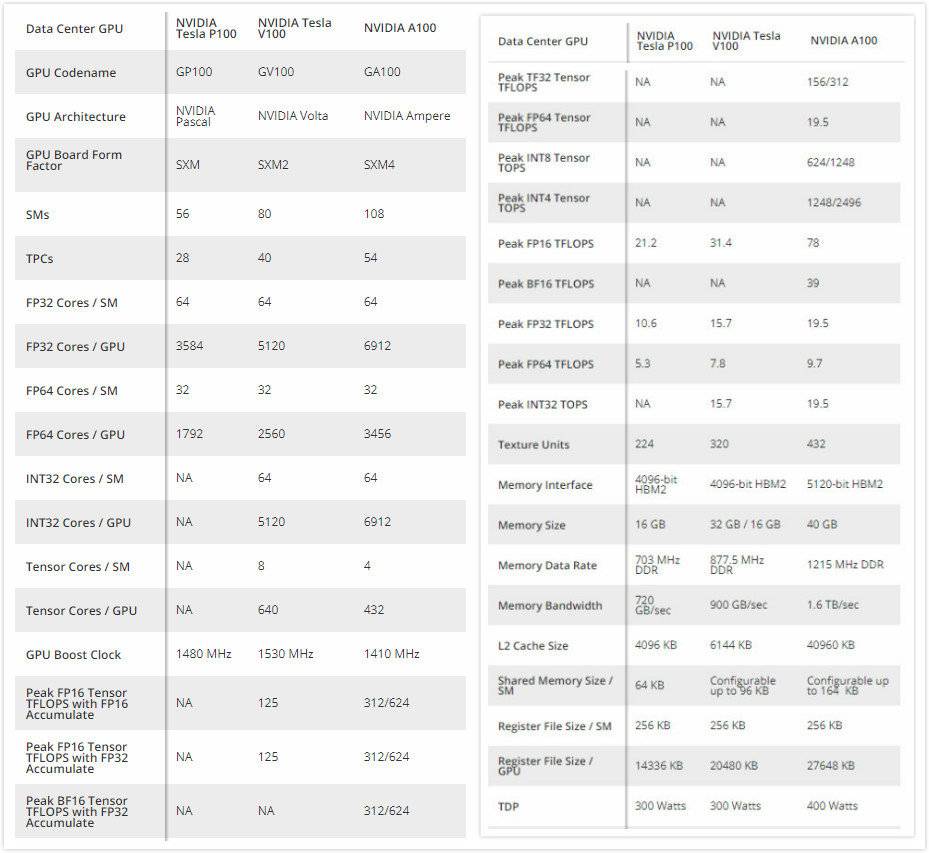
图片来自硬件评测媒体Tom’s hardware
而在许多GPU产品客户与爱好者所关心的工艺制程方面,过去1年里黄仁勋在多个场合被质问的“何时会缩短制程”这个问题,终于有了一个让人满意的答案。
让我们反向来看制程这个问题。
根据英伟达给出的这块A100尺寸来看,相当于制造者在一块826平方毫米的模具上塞进了540亿个晶体管;而V100则是在一块大约815平方毫米的模具上装有211亿个晶体管。
晶体管数量增长了2.5倍,但尺寸却仅大了1.3%。这代表差不多的身体,却装了双倍能量。
没错,这正是得益于芯片代工巨头台积电从12nm制程到7nm制程的技术升级。
“这在很大程度上让英伟达的显卡迷们松了一口气。毕竟两年前,英伟达在消费级市场的老对手AMD就推出了7nm GPU,而英伟达迟到了近2年。不过鉴于后者在2B商用领域的领先地位,这个时间点并不算晚。”
一位芯片从业者认为,英伟达最近预定台积电的5nm订单,也在一定程度上有了赶超对手制程的“进取心”。
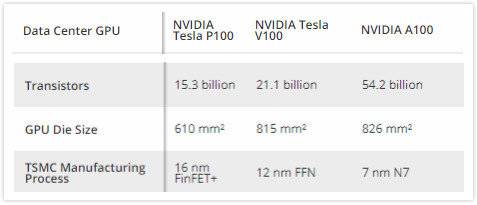
尺寸与制程,这尺寸的确大,的确是迄今为止最大的显卡
不过,虽然芯片测评专家们都发表了对英这块英伟达“新炸弹”的专业看法。但遗憾的是,或许是由于英伟达在游戏行业里拥有太大的影响力,以至于没有太多人关注这块企业级芯片为云端应用技术做了哪些微妙的调整。
刚才我们提到,在数据中心的环境下,执行大规模线上机器学习任务,需要多机多卡同时运行,参见很多国内外大学成立的超级计算项目,以及全国上亿人可能在同时使用的各种平台(淘宝、百度、抖音等等)的智能化搜索与个性化推荐。
因此,如何有效分配这些“多机多卡”的算力,是云计算工程师们特有的关注点:
“你会发现,A100新增了一个叫MIG的功能。根据描述,这个功能允许在单个A100上做资源隔离,能最多分割为7个独立GPU。”
正在研发基于异构计算架构数据处理平台的开源技术创业公司Zilliz合伙人、高级架构师顾钧,首先注意到了这个面向云端应用的新功能。
“这可以看作是一种让更多人分享GPU能力的方式。换句话说,每个人分到的GPU资源都是互相隔离的,不会发生互相干扰,抢占算力的情况,同时也能让GPU的投资回报率达到最大化。我估计这也是为云端容器化提供便利。”
云端容器化,是当前最为主流的云计算技术之一。
简单来说,用这项技术就是为了降低算力成本,将每个可能会互相争抢算力资源的云端任务,隔离在一个个孤立的“瓶子”里,做到互不打扰。
同时,又能根据任务的更迭,对其所需要的资源进行灵活的资源调度。
“举个例子,一块CPU假定有24个核(48线程),在容器化后,是可以把一个CPU的某个部分,譬如4个核8线程分配给一个容器。但之前GPU是没办法这么切分的。”顾钧解释。
因此,很多院校和企业此前大多在利用英伟达提供的vGPU虚拟化技术来“切分”GPU,分着给大家用,主要目的就是为了提高使用效率,降低计算成本。
譬如,VMware 中国研发先进技术中心的技术总监张海宁曾给给一所大学设计过vGPU切换方案:
白天学生做开发练习的简单任务,就切成4块,让4个人一起使用GPU;到了晚上项目要做模型训练,算力需求加大,就切换回1:1,确保100%算力。
当然,需要购买成千上万块企业级GPU的大型云服务商,会更加“吝啬”。用阿里工程师的一句玩笑话就是:“V100这么贵,当然要仔细琢磨怎么切得最划算,同时还能让利用率最大化。”
但也有人指出,这种GPU虚拟化技术对性能有一定的损耗,同时也会让机器启动速度变慢。而容器技术则会在一定程度上避免这些问题。
因此,让企业级GPU的设计对云端容器化更加“友好”,或许是一种产业里乐见其成的趋势。
根据调研机构Grand View Research在2019年12月发布的一份报告显示,到2025年,全球云端容器应用市场规模有望达到82亿美元,年增长率约为26.5% 。
而与此相呼应的一个论点,是硬件虚拟化(虚拟机)将会逐渐被容器技术所取代。
如此来看,英伟达的确在加大对自己的新摇钱树——企业级用户的“关怀”。
不必非要英伟达?
实际上,早在A100正式发布前,基本所有Top级云服务商都拿到了价值20万美元的新GPU系统(单个包含8块A100)。
当然,即便拿的是折扣价,也有工程师也暗暗吐槽说,“真贵,V100就很贵了,A100就更别提了。”
参见在海外新闻社区Reddit上,曾有人晒出自己嵌着8块V100的基板,立马被网友群起而攻之,炮轰为“可耻晒富行为”的行业趣闻。我们就能够感受到,云服务厂商为了大规模深度学习训练而采购成千上万块企业级GPU的财务压力有多大。
昂贵,是所有英伟达客户难得给出的统一观点。
有技术专家向虎嗅指出,英伟达的企业级芯片,仍然算是走“高端路线”的小众玩家。
譬如发布的最高性能的芯片都是先“特供”给一些拥有大规模人工智能训练项目的高校实验室,或者是做高级别自动驾驶的创业公司。单价高昂,但采购规模有限。
这又在一定程度上证明,谷歌(GOOG.US)、亚马逊(AMZN.US)、微软(MSFT.US)、阿里等云服务商自研云端AI训练或推理芯片是大势所趋的;但目前来看,自研产品发挥的作用还是有限的。
不过这至少意味着,尽管英伟达地位稳固,但跌下神坛并非不可想象。
“其实不仅仅是成本层面,随着深度学习和音视频转码的场景越来越复杂,单纯的GPU云服务器机型可能并不能满足所有需求。
所以现在大多云服务厂商都推出了基于FPGA、NPU等芯片的不同服务器机型。还有一些针对云游戏、推理等场景的轻量级vGPU。” 一位半导体行业人士认为,随着很多其他芯片巨头陆续推出不同的方案,英伟达并非是唯一的选择。
此外,他认为虽然理论上,GPU卡越多,整体算力越大。但是随着服务器数量的增加,不同机器的GPU之间配合难度也会越来越大,单张GPU卡的利用率反而会下降。
“所以说,增加了几十倍的卡成本,但性能却很难随之线性增长。”
然而,英伟达的聪明之处,或许就在于“小”到在一块芯片上顺应主流技术趋势,“大”到也在试图让孤立于不同服务器内的GPU卡之间产生更好的集群效应。
没错,在历时1年击败英特尔、赛灵思等强大竞争对手,最终完成对Mellanox的收购后,这家网络技术隐形巨头正式成了英伟达在数据中心市场的第二条“护城河”。
如同上面所说,处理海量数据和数据迁移所需的计算能力必须非常强大。而显而易见的问题是,这些数据通常存储在服务器无法立即访问的存储空间中。
如果网络不能有效利用这些数据,让数据之间产生流动,那么世界上所有的计算能力就不再重要了。
因此,利用Mellanox最擅长的通信技术,理论上,便能够将数据中心数万个计算节点上的GPU连接起来,汇聚成更加庞大的算力。
很显然,面对正在全球不断扩建,数量正在急剧增长的数据中心,这无疑是英伟达一个非常重要的竞争优势。
腾讯云资源管理总监阮梦在前几天的一场小型数据中心交流会曾指出,从2019年数据中心建设的走向来看,虽然相比北美超大型数据中心,我国在这个领域还有很多不足,但国内超大型数据中心的建设已悄然提速。
“随着数据中心建设速度加快,我们服务器量级会从100万台,往200万-400万这种级别去发展。
所以一方面服务器采购投入会持续加大,另一方面,服务器之间非常需要好的网络质量和网络互联。”
必要的硬件与软件升级,当然就需要采用更适合复杂云上任务训练的企业级AI芯片,以及更加灵活和多样化的服务器结构。
“就目前来看,在通用型服务器中,GPU的使用占比还非常小,合适的任务还没有那么多。但GPU部署的增速是非常快的。”
不过腾讯云技术中心资深技术专家李典林也指出,对于数据中心建设者来说,考虑的绝不仅仅是服务器等硬件成本问题。
“譬如一线城市周边合适的建设地点就相对紧缺,但一些偏远地区的网络条件就没有那么好。
而且GPU模块的功耗比普通服务器芯片要大很多,所以要进行特殊的机房设计与网络设置,那电力方面是不是要争取更多的优惠……
但从整体来看,这是一个不可忽视的数据中心变革趋势。”
而国家对新基建的推动浪潮,似乎又在进一步催化这个趋势。
因此,不知随着英伟达Ampere企业级GPU的发布与量产,以及阿里等云计算巨头们云端芯片在2020年商用速度的进一步加快,会不会给中国云计算基础设施市场带来新一轮洗牌。
资本市场的胜利者
由此来看,借着V100、T4等产品在数据中心打开的市场切口,英伟达推出这块被黄仁勋自嘲是“史上最大显卡”的目的,就是自己在华尔街近1年来受到众星捧月般待遇的最大缘由:
新兴企业级市场——数据中心的巨大商业前景,亟待英伟达的显卡来挖掘。
因此,你暂时只会在微软、阿里、腾讯等云服务商的数据中心,或是知名高校的大型实验室里,看到老黄端出来的那盘嵌着8块A100 GPU的DGX™ A100 服务器系统。
而单个系统价格,就高达20万美元。
这也可以解释,为何基于Ampere新架构的A100一发布,大部分消费级芯片评测网站的“表情”颇为复杂:虽然A100很强大,但跟我们好像没什么关系。
然而,站在英伟达投资者与股价的角度来看,这个产品是一个让人非常满意的结果。
在2020年3月发布的英伟达2020年Q1财报中,数据中心业务为公司整体收入贡献了近1/3。
某种程度上,这是第一次用确凿的财务数字,印证了企业级GPU产品在这个B端市场拥有巨大的收益增长空间。
因此,“数据中心”也被越来越多的分析师认定为下一个蕴藏着巨大商业潜力的蓝海市场。
有意思的是,早在2个月前,一向对芯片产品本身不会做过多评价的财经媒体彭博,在若干分析师纷纷上调了对英伟达的股价目标后,主动向外界表达了自己对英伟达发布新产品的期待:
“英伟达基于Ampere架构的新一代GPU,可能是其2016年以来最有前途的一款芯片。这款芯片或许会带来一系列令人惊喜的收益。”
此外,就在新产品发布前一天,也就是5月13日,英伟达股价上涨2.6%。证券公司Wedbush 分析师顺势调高股价目标,并发表如下言论:
“数据中心市场走势如此被外界看好,而在这一领域具备绝对地位的英伟达,可能在新品发布后会迎来更大的市值增长空间。”
而诸如老对手英特尔与AMD、服务器厂商以及各大云服务巨头,都在数据中心里嗅到了技术变革的味道,疯狂寻找新的商业机会。
英伟达,无疑是其中不可忽视的新技术掌舵者之一。
到这里,你应该能清楚,为何英伟达会把一个最新的架构,首先用在了一块企业级芯片里。
(编辑:李国坚)



 扫码下载智通APP
扫码下载智通APP